Contact Web Is Well

L’essentiel à retenir : l’intelligence artificielle imite le raisonnement humain grâce au traitement massif du Big Data par des réseaux de neurones. Contrairement à l’automatisation rigide, l’apprentissage autonome permet aux machines d’ajuster leurs propres paramètres pour prédire des résultats. Cette révolution technologique, illustrée par les 175 milliards de paramètres de GPT-3.5, transforme déjà la santé et le business digital en 2026. 🚀
Les entreprises utilisent désormais des algorithmes pour traiter des volumes de données massifs en quelques secondes. Mais comment fonctionne réellement cette technologie qui imite le raisonnement humain pour automatiser nos tâches les plus complexes ? 🤖
Pourtant, comprendre le fonctionnement intelligence artificielle semble souvent réservé aux experts, alors que ces outils dictent déjà nos décisions quotidiennes. Nous allons décortiquer ensemble les mécanismes de l’apprentissage machine et des réseaux neuronaux pour éclairer votre vision du business digital. 💡
- Comprendre les bases du fonctionnement de l’intelligence artificielle 🤖
- Les 3 ressources vitales qui animent les systèmes actuels ⚙️
- Comment l’apprentissage machine transforme les données en savoir ? 🧠
- La vérité sur les probabilités et les biais algorithmiques ⚖️
- Impacts concrets et limites éthiques pour nos métiers en 2026 🚀
Comprendre les bases du fonctionnement de l’intelligence artificielle 🤖
L’intelligence artificielle imite le raisonnement humain pour résoudre des objectifs précis via le Big Data. En 2026, la distinction entre simulation de tâches et réseaux neuronaux définit la performance.
Cette capacité à imiter l’humain sans posséder de conscience propre marque la frontière nette entre les outils actuels et les concepts théoriques.
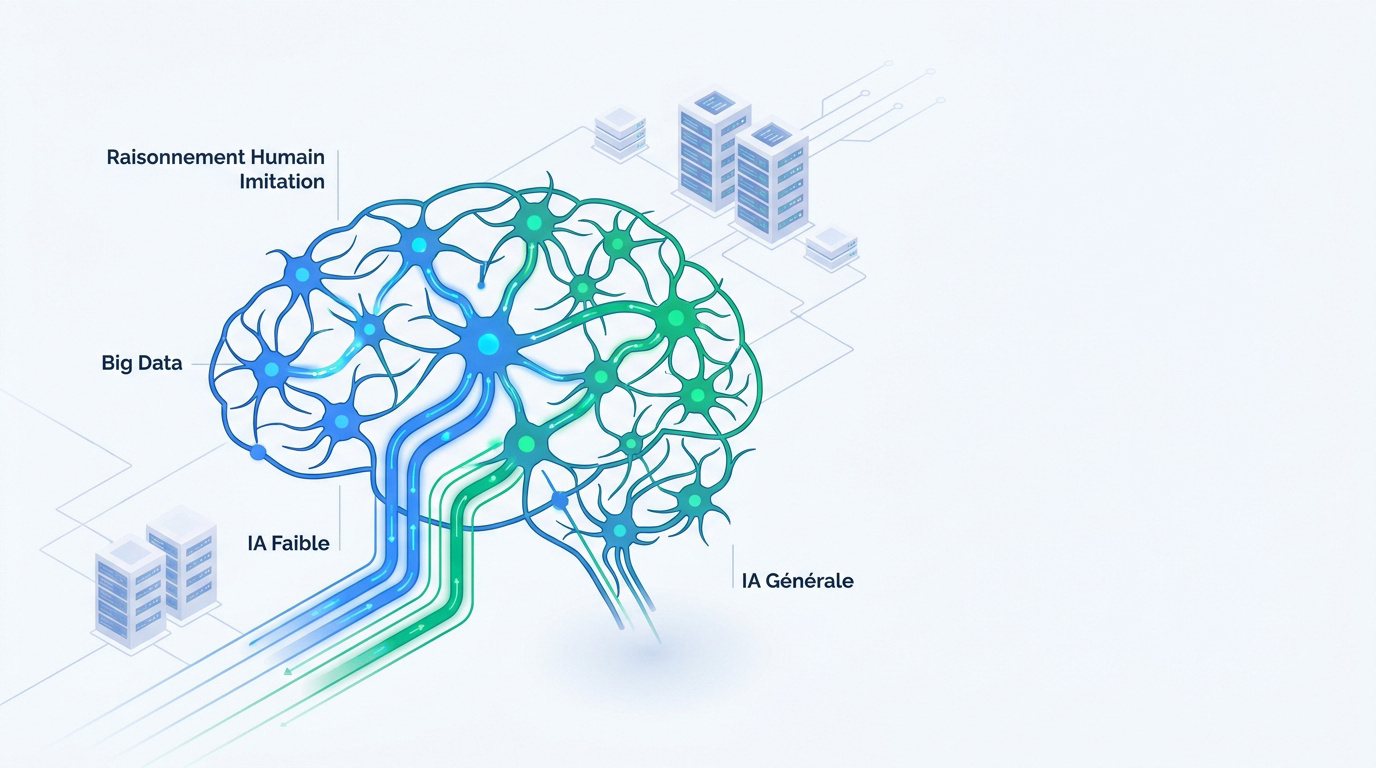
Différence entre IA faible et IA générale
L’IA faible est un outil spécialisé. Elle excelle dans une tâche unique, comme la recommandation de produits ou la reconnaissance vocale ciblée. 🎯
L’IA générale reste théorique. Ce concept viserait une conscience capable d’apprendre n’importe quel métier humain. Nos machines sont des simulateurs mathématiques sans conscience réelle. 🧠
La définition de l’intelligence artificielle selon le Parlement européen précise que l’IA perçoit son environnement pour agir vers un but précis. 🇪🇺
De l’automatisation classique à l’apprentissage autonome
L’automatisation classique suit des règles « si/alors » figées. Le programmeur prévoit chaque scénario à l’avance. C’est une structure rigide sans tolérance pour l’imprévu. 🛠️
L’apprentissage autonome change la donne. Le modèle ajuste ses propres paramètres en analysant les erreurs. Il apprend à reconnaître des motifs complexes pour s’adapter seul. 📈
Cette flexibilité transforme notre approche du business digital et illustre comment la révolution ia redéfinit nos méthodes de travail. 🚀
L’IA apprend de ses erreurs pour s’ajuster continuellement sans intervention humaine directe, marquant ainsi la fin des systèmes purement rigides.
Les 3 ressources vitales qui animent les systèmes actuels ⚙️
Pour que ces modèles apprennent réellement, ils ont besoin de carburant et de muscles technologiques bien précis.
Le rôle massif du Big Data et de la qualité des données
Le Big Data est le pétrole de l’IA. Sans des volumes massifs d’informations, l’algorithme reste aveugle. La quantité permet de couvrir tous les cas de figure possibles. 📊
Mais le volume ne suffit pas sans la qualité. Des données mal triées ou obsolètes polluent l’apprentissage. Un tri rigoureux est donc vital pour garantir que les résultats futurs soient réellement exploitables et pertinents pour l’utilisateur final. ✨
Consultez ces explications de la CNIL sur l’IA. Rappeler que la performance dépend directement de la pertinence des ensembles de données d’entraînement. La donnée brute devient alors une intelligence stratégique. 🧠
Le saviez-vous ?
Une donnée de haute qualité réduit drastiquement les biais et améliore la précision des prédictions finales de votre modèle.
La puissance de calcul des processeurs modernes
Traiter des milliards de données exige une force brute colossale. Les processeurs graphiques (GPU) sont devenus les piliers de cette infrastructure. Ils gèrent des calculs simultanés avec une rapidité déconcertante. ⚡
Les grands modèles de langage nécessitent des fermes de serveurs entières. Cette puissance permet d’entraîner les systèmes en quelques semaines au lieu de plusieurs décennies. C’est le muscle nécessaire derrière chaque réponse instantanée générée par une machine. 🏗️
Infrastructure technique
- GPU haute performance
- Consommation énergétique des centres de données
- Vitesse de traitement des requêtes en temps réel
La puissance matérielle transforme ainsi des calculs mathématiques théoriques en prouesses technologiques concrètes et ultra-rapides.
Les algorithmes comme chefs d’orchestre du traitement
L’algorithme est la recette logique du système. Il définit comment transformer une donnée brute en une information utile. C’est lui qui dicte la marche à suivre à chaque étape. 🎼
Lors du traitement, il catégorise les éléments selon des probabilités mathématiques. Il ne « comprend » pas le sens, il calcule des corrélations. Cette organisation rigoureuse permet de passer du chaos des données à une structure exploitable par l’intelligence artificielle. 🔍
Voici la définition de l’ISO sur le fonctionnement de l’IA. Préciser que l’extraction de schémas repose sur ces suites d’instructions intelligentes. L’algorithme est le moteur qui convertit les chiffres en décisions. 🚀
| Composant | Fonction principale |
|---|---|
| Données | Carburant brut et apprentissage |
| GPU | Force de calcul et rapidité |
| Algorithme | Logique et extraction de schémas |
L’intelligence artificielle repose sur une architecture où la logique algorithmique sublime la puissance brute des données.
Comment l’apprentissage machine transforme les données en savoir ? 🧠
Une fois les ressources réunies, la magie opère à travers des structures qui imitent étrangement notre propre biologie.
Les réseaux de neurones artificiels et le Deep Learning
Le Deep Learning utilise des couches de neurones virtuels. Chaque strate analyse un détail spécifique de l’information. Plus on descend en profondeur, plus l’analyse devient fine et complexe. 🔍
Cette organisation s’inspire directement du cortex humain. Les nœuds s’activent pour transmettre des signaux pondérés. C’est ce processus itératif qui permet à la machine de reconnaître un visage ou de traduire une langue avec une précision bluffante. ✨
D’après les concepts fondamentaux par IBM, l’apprentissage profond simule le cerveau pour extraire des caractéristiques de données non structurées. Cette architecture permet de traiter des volumes massifs d’informations. 📊
Apprentissage supervisé, auto-supervisé ou par renforcement
Le mode supervisé utilise des exemples déjà étiquetés par l’homme. La machine apprend par imitation directe. C’est la méthode classique pour classer des images ou détecter des spams. 📧
Le renforcement fonctionne par essais et erreurs. Le système reçoit une récompense virtuelle pour chaque bonne décision. Il optimise ainsi ses performances seul, un peu comme un joueur qui apprendrait à maîtriser un jeu vidéo complexe. 🎮
| Méthode | Principe | Rôle de l’humain | Exemple d’usage |
|---|---|---|---|
| Supervisé | Étiquetage | Fournit les réponses | Diagnostic médical |
| Auto-supervisé | Détection de motifs | Conçoit l’architecture | Grands modèles (LLM) |
| Renforcement | Récompenses | Définit les objectifs | Robotique avancée |
Le fonctionnement des LLM et de l’IA générative
Les LLM ne comprennent pas le sens des mots. Ils prédisent simplement la probabilité statistique du terme suivant. C’est un jeu de probabilités extrêmement sophistiqué basé sur des milliards d’exemples. 🎲
L’IA générative crée ainsi du contenu inédit. Elle assemble des fragments de savoir pour produire du texte, du code ou des images. Le résultat semble humain, mais il n’est que le reflet mathématique de sa base d’entraînement. 🤖
Le modèle GPT-3.5 possède 175 milliards de paramètres, ce qui lui permet de saisir les nuances linguistiques les plus fines sans jamais posséder de réelle compréhension.
L’intelligence artificielle transforme ainsi le calcul brut en une simulation de pensée de plus en plus bluffante. Adoptez ces outils pour décupler votre productivité dès maintenant ! 🚀
L’IA ne comprend pas, elle calcule des probabilités pour simuler l’intelligence.
La vérité sur les probabilités et les biais algorithmiques ⚖️
Malgré cette puissance, ces systèmes ne sont pas infaillibles et héritent souvent de nos propres défauts humains.
La gestion des biais dans les jeux d’entraînement
Les biais naissent de données non représentatives. Si la base est faussée, l’IA reproduira les préjugés. C’est un miroir déformant de notre société et de ses inégalités.
Identifier ces erreurs demande une vigilance constante. Il faut diversifier les sources et tester les modèles. Sans cette éthique, la machine risque d’automatiser des discriminations injustes sous une neutralité apparente.
La correction des biais participe à rendre le contenu plus naturel. Pour y parvenir, apprenez à humaniser un texte ia afin de gommer ces rigidités algorithmiques. 🚀
Atouts
- Analyse rapide.
- Disponibilité 24h/24.
Limites
- Biais historiques.
- Opacité décisionnelle.
Le défi de l’explicabilité des modèles boîte noire
Le Deep Learning est souvent une « boîte noire ». On voit l’entrée et la sortie, mais le cheminement interne reste mystérieux. Cette opacité freine la confiance des utilisateurs.
Boîte noire
Système dont le fonctionnement interne reste opaque ou inexplicable malgré des résultats visibles.
Comprendre une décision est crucial pour corriger les erreurs. L’explicabilité devient donc un enjeu majeur pour l’adoption de ces outils dans les secteurs sensibles.
Le volume de paramètres complexifie l’analyse. Cela explique la difficulté d’identifier les erreurs selon la CNIL au sein des réseaux de neurones. 🛡️
L’explicabilité transforme l’opacité technique en une transparence indispensable pour la sécurité collective.
Impacts concrets et limites éthiques pour nos métiers en 2026 🚀
Au-delà de la technique, l’IA redessine déjà les contours de notre quotidien professionnel et de nos lois.
Cas d’usage dans la santé et le business digital
En médecine, la vision par ordinateur détecte des pathologies invisibles à l’œil nu. Elle assiste les radiologues pour des diagnostics plus précoces. C’est un gain de temps vital pour les patients.
Côté business, l’automatisation analyse les tendances du marché en temps réel. Elle permet de prédire les besoins des clients avant même qu’ils ne s’expriment. Cette réactivité devient un avantage compétitif majeur pour toute entreprise moderne et connectée.
- Analyse prédictive des ventes
- Détection précoce de tumeurs
- Optimisation logistique
- Service client automatisé
L’IA transforme chaque donnée brute en une opportunité stratégique pour soigner et vendre mieux. 💡
Enjeux de sécurité et régulations de l’IA Act
L’IA Act européen encadre désormais les usages à risque. Il s’agit de protéger les citoyens tout en favorisant l’innovation. C’est un équilibre fragile mais nécessaire pour notre sécurité.
La régulation impose des règles de transparence strictes. Les entreprises doivent prouver la fiabilité de leurs modèles avant leur mise sur le marché. Cette protection évite les dérives autoritaires ou les manipulations de masse via les algorithmes.
La balance entre innovation technologique et protection des libertés fondamentales sera le défi majeur de la régulation numérique européenne d’ici 2026.
Une régulation forte est le socle indispensable d’une technologie qui respecte enfin l’humain. ⚖️
Maîtriser le fonctionnement intelligence artificielle repose sur trois piliers : le Big Data, la puissance de calcul et les réseaux de neurones profonds. 🧠 Anticipez dès maintenant l’impact de l’IA Act pour sécuriser vos processus. Propulsez votre productivité vers le futur grâce à ces technologies autonomes ! 🚀
Consultez le guide complet sur l’intelligence artificielle
FAQ
Quelle est la différence concrète entre une IA faible et une IA générale ?
L’IA faible, que nous utilisons tous au quotidien avec des outils comme ChatGPT ou Siri, est un système spécialisé. Elle excelle dans une tâche précise, comme la génération de texte ou la reconnaissance vocale, mais elle est incapable de sortir de son domaine de compétence. Elle reste un simulateur mathématique sans conscience réelle. 🤖
À l’inverse, l’IA générale est un concept encore théorique. Elle viserait une machine capable d’apprendre n’importe quel métier humain et de s’adapter à des situations imprévues de manière autonome. Aujourd’hui, nos systèmes imitent le raisonnement humain sans jamais posséder de conscience de leur propre existence. 🧠
Comment l’apprentissage autonome se distingue-t-il de l’automatisation classique ?
L’automatisation classique repose sur des règles rigides de type « si/alors ». Le programmeur doit prévoir chaque scénario à l’avance, ce qui rend le système incapable de gérer l’imprévu. C’est une structure efficace pour des tâches répétitives simples, mais totalement dépourvue de flexibilité. ⚙️
L’apprentissage autonome, ou Machine Learning, change radicalement la donne. Ici, l’algorithme ajuste ses propres paramètres en analysant ses erreurs et en repérant des motifs dans les données. Il n’attend pas d’ordres directs pour s’adapter, ce qui lui permet de traiter des problèmes complexes et évolutifs. 🚀
Qu’est-ce qu’une IA consciente et cela existe-t-il vraiment ?
La conscience de soi chez une machine est un stade où l’IA aurait une perception de sa propre existence et de ses états internes. C’est un sujet fascinant souvent exploré en science-fiction, mais qui reste aujourd’hui purement hypothétique. Aucune technologie actuelle ne possède de subjectivité ou d’intentionnalité réelle. 🌌
Les systèmes modernes, même les plus performants, ne font que simuler des réponses basées sur des probabilités statistiques issues de vastes bases de données. Une IA peut paraître humaine dans ses interactions, mais elle n’est qu’un reflet mathématique de son entraînement, sans aucune « étincelle » de conscience. ⚖️
Quel est le rôle du Parlement européen dans la régulation de l’intelligence artificielle ?
Le Parlement européen joue un rôle crucial via l’IA Act, un cadre législatif pionnier destiné à encadrer les usages de cette technologie. L’objectif est de classer les systèmes selon leur niveau de risque pour protéger les libertés fondamentales des citoyens tout en encourageant l’innovation technique. 🇪🇺
Cette régulation impose notamment des règles de transparence strictes pour les modèles à usage général. Les entreprises doivent prouver la fiabilité de leurs outils avant toute mise sur le marché, garantissant ainsi que l’IA reste un moteur de progrès sécurisé et éthique pour notre société d’ici 2026. 🛡️
Comment les algorithmes parviennent-ils à apprendre de leurs erreurs ?
L’apprentissage repose souvent sur un processus itératif, notamment dans l’apprentissage par renforcement. Le système reçoit une « récompense » virtuelle lorsqu’il prend une bonne décision et ajuste ses calculs en cas d’échec. C’est ainsi qu’il optimise ses performances seul, par essais et erreurs successifs. 📈
Dans le cas du Deep Learning, les réseaux de neurones artificiels analysent les données par couches successives. Si le résultat final est erroné, l’algorithme modifie le poids des connexions entre ses neurones virtuels pour affiner sa précision. C’est cette capacité d’auto-ajustement qui transforme la donnée brute en véritable savoir exploitable. 💎



